HTTP各版本特性
HTTP 0.9
1991年发布
基本上只是一个草稿,设计的初衷只是为了获取简单的HTML对象。只支持GET。没怎么使用就被HTTP 1.0代替了。
HTTP 1.0
1996年5月发布规范 rfc1945
第一个广泛使用的版本。
相比HTTP 0.9:
增加了对多媒体对象的处理,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。
增加了一些方法:POST,HEAD。丰富了浏览器与服务器的互动手段。
新增了HTTP首部。比较重要的有Content-Type ,Content-Length,Content-Encoding
HTTP请求和响应格式的改变。
其他新增功能。比如状态码的定义。
请求报文:
1 | 请求行 eg:GET /u/2167612f3a86 HTTP/1.1 |
响应报文:
1 | 响应行 eg:HTTP/1.1 200 OK |
HTTP/1.0 缺点:
HTTP/1.0 版的主要缺点是,每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。所以,HTTP 1.0版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。
为了解决这个问题,在还没出HTTP/1.1规范时,各个公司可能会有一些自己的优化手段。有些浏览器在请求时,用了一个非标准的Connection字段。
1 | Connection: keep-alive |
Connection头部,用于决定当前的事务完成后,是否会关闭网络连接。
如果该值是“keep-alive”,网络连接就是持久的,不会关闭,使得对同一个服务器的请求可以继续在该连接上完成。
如果该值是“close”表明客户端或服务器想要关闭该网络连接。
像这种做的比较好的优化可能就会被放到下一次的RFC规范中去。Connection头部就被HTTP/1.1规范所采用。
HTTP 1.1
1999年6月发布规范 rfc2616
进一步完善了 HTTP 协议,一直用到了20年后的今天,直到现在还是最流行的版本。
相比HTTP/1.0:
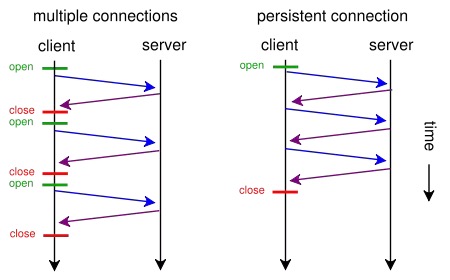
1.引入了持久连接(persistent connection)
通过Connection头部控制,HTTP/1.0默认是close,HTTP/1.1默认是keep-alive。请求完成后TCP连接默认不关闭,因此可以被多个请求复用。
在HTTP 1.0中,没有官方的keepalive操作。通常是在现有协议上添加一个首部。如果浏览器支持keep-alive,它会在请求的包头中添加:
1 | Connection: -Alive |
然后当服务器收到请求,作出回应的时候,它也添加一个头在响应中:
1 | Connection: -Alive |
这样做,连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个连接。这一直继续到客户端或服务器端认为会话已经结束,其中一方中断连接。
在HTTP 1.1中所有的连接默认都是持续连接,除非特殊声明不支持。
持久连接的好处:
1 | Persistent HTTP connections have a number of advantages: |
RFC 上列举了这么多其实就两点
- 持久连接为连接的复用提供基础,从而减少了额外的TCP连接,以及TCP刚连接时的慢启动带来的损耗。
- 持久连接为管线机制提供基础。
注意:使用持久连接时,就不能通过连接的断开作为报文的终止符了。每个报文最好提供一个Content-Length要不然没法区分各报文的边界。而对于动态生成的文件因为无法提供content-length,所以最好采用分块(chunked)传输,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束。
使用了持久连接对比图:
2.管线机制(Pipelining)
在使用持久连接后,管线机制可以让客户端在上一个响应还没回来时就可以发送下一个请求。但是服务器端返回的响应的顺序必须按照接收到的请求的顺序来发送(如果服务器没有按照该规则实现的话,客户端接收到的将是混杂数据)。参考 AF issue #528
比如服务器收到客服端发来的A-B-C三个请求,那么返回响应时必须A的响应发完后才能再发B的,B的发完后再发C的。
聪明的你可能已经看到管线机制的缺点了,如果第一个请求需要处理的时间非常长,那么后续的请求即使已经被服务器处理完成,响应也不能立即返回,而是存储在服务端的缓存区中,等待第一个响应的完成,才能按照FIFO顺序返回。这就是队头阻塞。
正是由于存在这样或那样的问题,HTTP管道技术的应用比较有限,并没有大面积推广开来,基本上是关的,即使一些支持它的浏览器也仅仅把它作为一个高级选项。这些缺点将在HTTP2中得以解决。
使用了管线机制对比图:
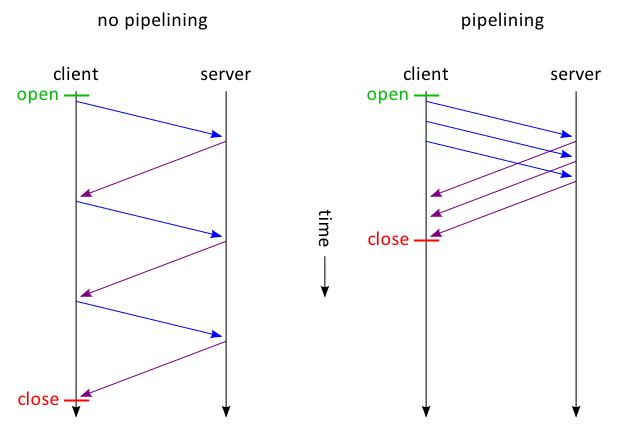
这里需要对pipelining图做一点解释
管线机制,A,B,C的响应数据是不可以交叉返回的。因为如果交叉的话,客户端根本无法区分收到的数据属于哪个请求。既然A,B,C的响应是顺序返回的也就是A的响应必须发完后才能再发B的,那么如果A是一个下载大文件的请求,B,C都是小数据请求,那么客户端将会等很久才能收到B,C的响应,这就是队头阻塞。

3.新增了一些方法
OPTIONS,PUT,DELETE,TRACE,CONNECT。
4.新增了一大波状态码
在HTTP1.1中新增了24个错误状态响应码。
5.完善了缓存机制
在 HTTP 1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP 1.1则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
关于HTTP的缓存机制这里不做展开,因为这又是一个很大的话题。
6.新增了一大波首部
比如跟缓存控制相关的就增加了很多,还有Content-Range, Host, Range等。
Host首部
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
7.带宽优化
HTTP/1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,又比如下载大文件时需要支持断点续传功能,而不是在发生断连后不得不重新下载完整的包。HTTP/1.1中在请求消息中引入了range头域,它允许只请求资源的某个部分。在响应消息中Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码为206(Partial Content),它可以防止Cache将响应误以为是完整的一个对象。
另外一种情况是请求消息中如果包含比较大的实体内容,但不确定服务器是否能够接收该请求(如是否有权限),此时若贸然发出带实体的请求,如果被拒绝也会浪费带宽。HTTP/1.1加入了一个新的状态码100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码401(Unauthorized);如果服务器接收此请求就回送响应码100,客户端就可以继续发送带实体的完整请求了。注意,HTTP/1.0的客户端不支持100响应码。但可以让客户端在请求消息中加入Expect头域,并将它的值设置为100-continue。
8.分块传输编码
HTTP消息中可以包含任意长度的实体,通常它们使用Content-Length来给出消息结束标志。但是,对于很多动态产生的响应,只能通过缓冲完整的消息来判断消息的大小,但这样做会加大延迟。
1.1版规定可以不使用Content-Length字段,而使用“分块传输编码”(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。发送方将消息分割成若干个任意大小的数据块,每个数据块在发送时都会附上块的长度,最后用一个零长度的块作为消息结束的标志。
新增MIME类型 multipart/form-data 等。
HTTP/1.1缺点:
1.队头阻塞
在使用持久连接后,管线机制可以让客户端在上一个响应还没回来时就可以发送下一个请求。但是服务器端返回的响应的顺序必须按照接收到的请求的顺序来发送。如果第一个请求需要处理的时间非常长,那么后续的请求即使已经被服务器处理完成,响应也不能立即返回,而是存储在服务端的缓存区中,等待第一个响应的完成,才能按照FIFO顺序返回。这就是队头阻塞。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、雪碧图、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
另外HTTP连接也不是想开多少就开多少的,HTTP1.1,Chrome浏览器通常允许每个域名同时发出的最大连接数为6个。这意味着在同一个页面中,您可以同时发出6个同源请求。请注意,这个限制是针对每个域名的,如果您的页面使用了多个域名(例如使用CDN),那么您可以同时发出更多的请求。对于超过限制数目的请求会被阻塞直到一些请求完成才会继续发出。所以一些优化就会把资源放在不同的域名下。
What are the disadvantage(s) of using HTTP pipelining? 讨论管线机制的缺点的。里面参考资料中我大苹果WWDC2015里就已经对比了HTTP1.1和HTTP2的性能,奈何自己没看WWDC。作为一个iOS开发者,WWDC必看才行。
2.无状态特性 – 带来巨大的 HTTP 头部
由于报文 Header 一般会携带”User Agent” “Cookie”“Accept””Server”等许多固定的头字段(如下图),多达几百字节甚至上千字节,但 Body 却经常只有几十字节(比如 GET 请求、 204/301/304 响应),成了不折不扣的“大头儿子”。Header 里携带的内容过大,在一定程度上增加了传输成本。更要命的是,成千上万的请求响应报文里有很多字段值都是重复的,非常浪费。
SPDY协议
谷歌出品,于2009 年公开
因为 HTTP/1 的问题,我们会引入雪碧图、将小图内联、使用多个域名等等的方式来提高性能。不过这些优化都绕开了协议本身,直到 2009 年,谷歌公开了自行研发的 SPDY 协议,它主要解决 HTTP/1.1 效率不高的问题。
直到这时,才算是正式改造了 HTTP 协议本身。SPDY 进行延迟降低、header 压缩等改进,其实践证明了这些优化的效果,也最终带来了 HTTP/2 的诞生。
HTTP 2
2015年5月发布规范 rfc7540
相比HTTP/1.1:
1.二进制协议
之前的HTTP版本可以说是一个文本协议,需要按照一定的书写格式,双方才能正确解析。但HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
接下来我们介绍几个重要的概念:
- 流(Stream):流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2…N);
- 消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
- 帧:HTTP 2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流,承载着特定类型的数据,如 HTTP 首部、负荷,等等
一个 TCP 连接(HTTP2 连接建立在 TCP 连接之上)里可以发送若干个流(stream),每个流中可以传输若干条消息(message),每条消息由若干二进制帧(frame)组成。
注:流还是挺复杂的,具体可以看一下流的状态图。
HTTP 2的帧布局如下:

所有的帧都以一个固定的9字节的头开始,后面跟着的是长度可变的payload。
帧头字段的定义:
Length:24bit,无符号整型,最大2^14 (16,384) ,帧的长度还受到SETTINGS_MAX_FRAME_SIZE帧的限制。该值不包含固定的9字节帧头,就是payload的长度。
Type:8bit,代表帧的类型。比如DATA帧和HEADERS帧。对于各种帧可以抓包学习一下。
Flags:具体帧的标识
R:保留位。
Stream Identifier:流ID。无符号31位整型。值0是保留的。每个流都有一个唯一的整数 ID。流ID就是用来标识该帧属于哪个流的,这样一个连接上传输的帧才能知道自己属于哪个流,接收方才能正确的进行拼接帧不至于拼接了别的流的帧。可以预见单个流的所有帧之间是有序的。
RFC规定由客户端初始化的流使用奇数ID,由服务器初始化的流使用偶数ID,这里不是很懂,什么情况下服务器会初始化流?请求不都是由客户端发起的吗?
在RFC 8.2.2. Push Responses中有说明:
1 | After sending the PUSH_PROMISE frame, the server can begin delivering |
果然是服务器推送时,服务器会初始化流,此时流的ID就为偶数。
二进制分帧层
在不改动 HTTP/1.1 的语义、⽅法、状态码、URI 以及⾸部字段等等的情况下, HTTP/1.1 是如何转到HTTP/2呢?
答案就是HTTP/1.1 的报文先经过⼀个⼆进制分帧层将其转化为HTTP/2 二进制协议,后面的就是一样的了。
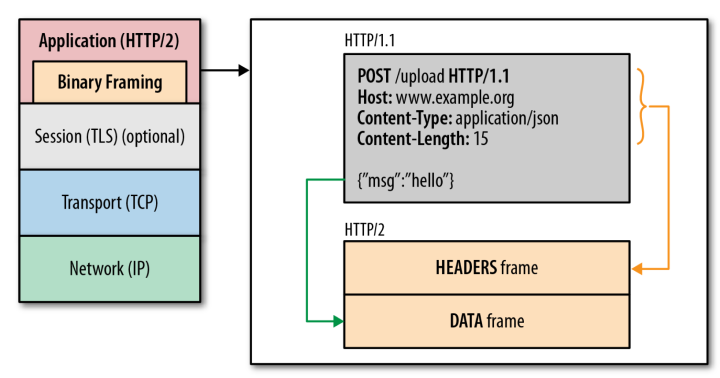
在 HTTP/2 中,有了二进制分帧之后,HTTP /2 不再依赖 TCP 链接去实现多流并行了,这一特性,使性能有了极大提升:
- 同个域名只需要占用一个 TCP 连接,使用一个连接并行发送多个请求和响应,消除了因多个 TCP 连接而带来的延时和内存消耗。
- 可以并行交错地发送多个请求,请求之间互不影响。
- 可以并行交错地发送多个响应,响应之间互不干扰。
- 在 HTTP/2 中,每个请求都可以带一个 31bit 的优先值,0 表示最高优先级, 数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
2.多路复用
HTTP/2 复用TCP连接,在一个连接里,客户端可以同时发送多个请求,服务器端回复的响应也不用按照顺序一一对应,这样就避免了”队头堵塞”。
客户端根据流ID来区分不同的帧从而分别得到A和B的响应。
3.Header 压缩
HTTP2.0 使用 HPACK 算法对 header 的数据进行压缩,减少请求的大小,减少流量消耗,提高效率。因为之前存在一个问题是,每次请求都要带上 header,而这个 header 中的数据通常是不变的。
4.Server Push
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析HTML源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
HTTP/2 缺点:
1.没有彻底解决队头阻塞
HTTP/2 并没有彻底解决队头阻塞,由于HTTP2是在一个TCP连接上发送请求,接收请求的。一旦出现丢包,丢失的包必须要等待重新传输确认,因此HTTP/2 出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该 TCP 连接中的所有请求。而对于 HTTP/1.1 来说,可以开启多个 TCP 连接,出现这种情况反倒只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
2.TCP 和 TCP+TLS 建立连接的延时
HTTP/2 是使用 TCP 协议来传输的。如果使用 HTTPS 的话,还需要使用 TLS 协议进行安全传输,而使用 TLS 也需要一个握手过程,这样就需要有两个握手延迟过程。
上面两个问题要动大刀才能解决,因为这是底层支撑的 TCP 协议造成的。要想优化的话,只能替换底层的TCP了。
HTTP/3及谷歌的QUIC协议(主要是谷歌,毕竟只要谷歌搞完后测试正常,RFC直接将其定为规范就完事了)就是为解决上述问题而提出的方案。
参考
QUIC和HTTP/3
HTTP/3 已于 2022年6月6日正式发布了,被标准化为 RFC 9114。
QUIC 基于 UDP,而 UDP 是“无连接”的,根本就不需要“握手”和“挥手”,所以就比 TCP 来得快。此外,QUIC 也实现了可靠传输,保证数据一定能够抵达目的地。它还引入了类似 HTTP/2 的“流”和“多路复用”,单个“流”是有序的,可能会因为丢包而阻塞,但其他“流”不会受到影响。
问题
为什么要复用连接?
HTTP耗时 = TCP握手
HTTPS耗时 = TCP握手 + SSL握手
1 | curl -w "TCP handshake: %{time_connect}, SSL handshake: %{time_appconnect}\n" -so /dev/null https://www.alipay.com |
上面命令中的w参数表示指定输出格式,time_connect变量表示TCP握手的耗时,time_appconnect变量表示SSL握手的耗时(更多变量请查看文档和实例),s参数和o参数用来关闭标准输出。另外青花瓷抓包也可以看到各阶段的耗时。
可以看到如果不复用连接,那么每次都要3次TCP握手建立TCP连接,7次SSL握手建立SSL连接,而这些连接的建立都需要耗时,特别是建立SSL连接耗时更大,差不多是TCP的2-3倍。
除了建立连接耗时外,TCP的慢启动机制也会影响传输速度。
因此从HTTP1.1版本开始就支持连接的复用了,只不过HTTP1.1版本的连接复用还不成熟,毕竟技术都有一个不断优化的过程,从来都不是一蹴而就的。
HTTP2,帧间顺序如何保证?
(网上的博客):流内部的帧是有严格顺序的(不确定是由协议字段来保证还是由发送端严格按照顺序发送来保证,感觉应该是由发送端来保证,因为协议里没有相关字段),但是流之间互相独立;流 ID 不能重用,只能顺序递增,客户端发起的 Stream ID 是奇数,服务器端发起的 Stream ID 是偶数;
HTTP1.1如何协商升级到HTTP2
1 | GET / |
如果服务端不支持 HTTP/2,它会忽略 Upgrade 字段,直接返回 HTTP/1.1 响应,例如:
1 | 200 OK |
如果服务端支持 HTTP/2,那就可以回应 101 状态码及对应头部,并且在响应正文中可以直接使用 HTTP/2 二进制帧:
1 | 101 Switching Protocols |
参考
HTTP 协议入门 阮一峰
rfc1945—Hypertext Transfer Protocol — HTTP/1.0
rfc2616—Hypertext Transfer Protocol — HTTP/1.1
rfc7540—Hypertext Transfer Protocol Version 2 (HTTP/2)
Hypertext Transfer Protocol Version 3 (HTTP/3)
HTTP/HTTPS协议 面试问题
HTTP/3详解 4
