// Begin synchronizing on 'obj'. // Allocates recursive mutex associated with 'obj' if needed. // Returns OBJC_SYNC_SUCCESS once lock is acquired. intobjc_sync_enter(id obj) { int result = OBJC_SYNC_SUCCESS;
if (obj) { SyncData* data = id2data(obj, ACQUIRE); ASSERT(data); data->mutex.lock(); } else { // @synchronized(nil) does nothing if (DebugNilSync) { _objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug"); } objc_sync_nil(); }
// // Allocate a lock only when needed. Since few locks are needed at any point // in time, keep them on a single list. //
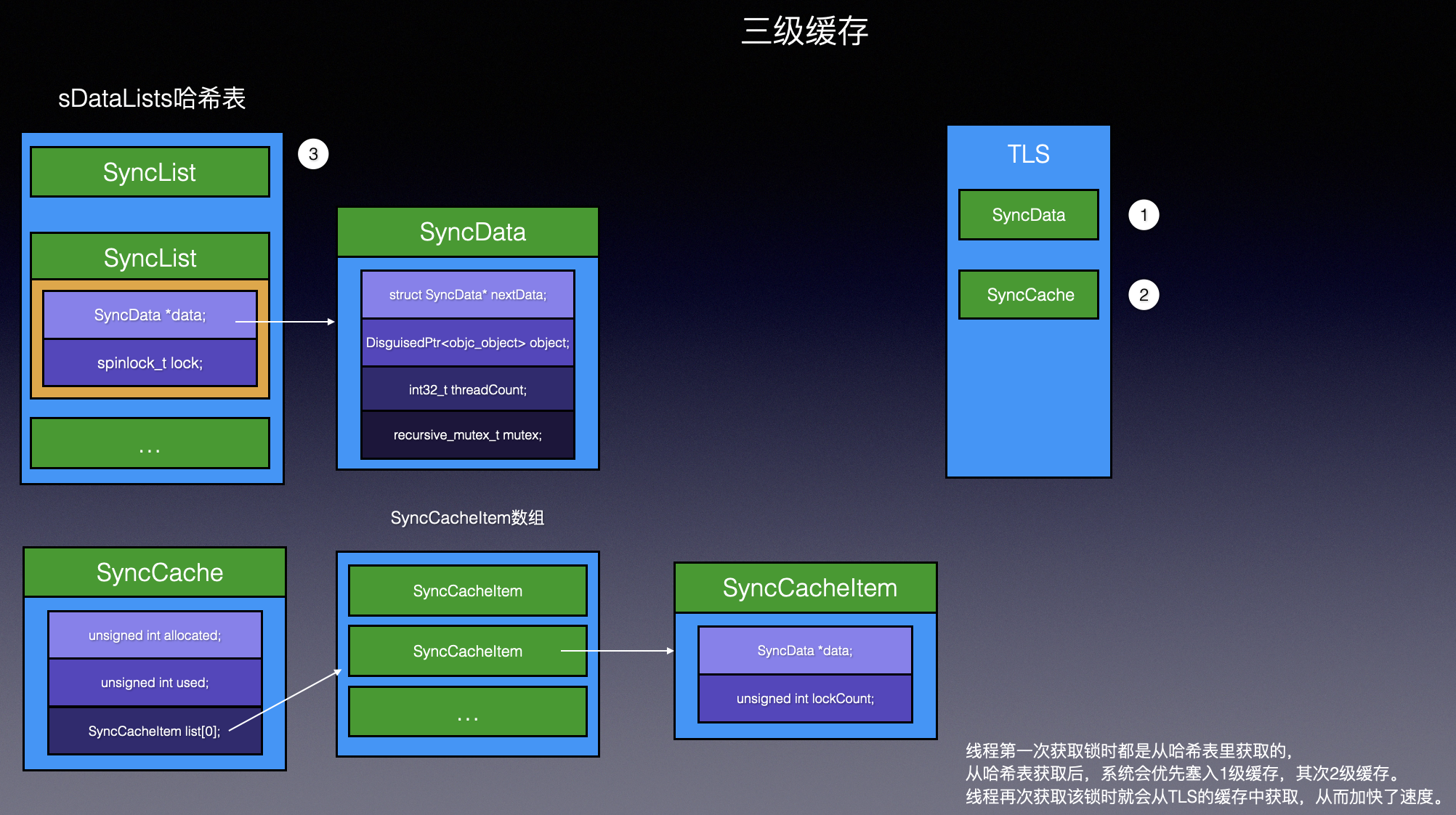
typedefstructalignas(CacheLineSize) SyncData { structSyncData* nextData; DisguisedPtr<objc_object> object; int32_t threadCount; // number of THREADS using this block。只会是0和1。0代表空闲,SyncData可被复用 recursive_mutex_t mutex; } SyncData;
nextData:指向下一个SyncData,因此SyncData是一个单链表。
object:传入的同步对象,DisguisedPtr类型,其实就是记录对象的地址
threadCount:使用该block的线程数,该计数器作用:
1用于安全判断
1 2 3
if (result->threadCount <= 0 || item->lockCount <= 0) { _objc_fatal("id2data cache is buggy"); }
// StripedMap<T> is a map of void* -> T, sized appropriately // for cache-friendly lock striping. // For example, this may be used as StripedMap<spinlock_t> // or as StripedMap<SomeStruct> where SomeStruct stores a spin lock. template<typename T> classStripedMap { #if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR enum { StripeCount = 8 }; #else enum { StripeCount = 64 }; #endif
structPaddedT { T value alignas(CacheLineSize); };
#if SUPPORT_DIRECT_THREAD_KEYS // Check per-thread single-entry fast cache for matching object bool fastCacheOccupied = NO; SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY); if (data) { fastCacheOccupied = YES;
if (data->object == object) { // Found a match in fast cache. uintptr_t lockCount;
result = data; lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY); if (result->threadCount <= 0 || lockCount <= 0) { _objc_fatal("id2data fastcache is buggy"); }
switch(why) { case ACQUIRE: { lockCount++; tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); break; } case RELEASE: lockCount--; tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); if (lockCount == 0) { // remove from fast cache tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL); // atomic because may collide with concurrent ACQUIRE OSAtomicDecrement32Barrier(&result->threadCount); //threadCount-1,很重要 } break; case CHECK: // do nothing break; }
return result; } } #endif
// Check per-thread cache of already-owned locks for matching object SyncCache *cache = fetch_cache(NO); if (cache) { unsignedint i; for (i = 0; i < cache->used; i++) { SyncCacheItem *item = &cache->list[i]; if (item->data->object != object) continue;
// Found a match. result = item->data; if (result->threadCount <= 0 || item->lockCount <= 0) { _objc_fatal("id2data cache is buggy"); } switch(why) { case ACQUIRE: item->lockCount++; break; case RELEASE: item->lockCount--; if (item->lockCount == 0) { // remove from per-thread cache cache->list[i] = cache->list[--cache->used]; // atomic because may collide with concurrent ACQUIRE OSAtomicDecrement32Barrier(&result->threadCount);//threadCount-1,很重要 } break; case CHECK: // do nothing break; }
return result; } }
// Thread cache didn't find anything. // Walk in-use list looking for matching object // Spinlock prevents multiple threads from creating multiple // locks for the same new object. // We could keep the nodes in some hash table if we find that there are // more than 20 or so distinct locks active, but we don't do that now. lockp->lock();
{ SyncData* p; SyncData* firstUnused = NULL; for (p = *listp; p != NULL; p = p->nextData) { if ( p->object == object ) { result = p; // atomic because may collide with concurrent RELEASE OSAtomicIncrement32Barrier(&result->threadCount); goto done; } if ( (firstUnused == NULL) && (p->threadCount == 0) ) firstUnused = p; } // no SyncData currently associated with object if ( (why == RELEASE) || (why == CHECK) ) goto done; // an unused one was found, use it if ( firstUnused != NULL ) { result = firstUnused; result->object = (objc_object *)object; result->threadCount = 1; goto done; } }
// Allocate a new SyncData and add to list. // XXX allocating memory with a global lock held is bad practice, // might be worth releasing the lock, allocating, and searching again. // But since we never free these guys we won't be stuck in allocation very often. posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); result->object = (objc_object *)object; result->threadCount = 1; new (&result->mutex) recursive_mutex_t(fork_unsafe_lock); result->nextData = *listp; *listp = result; done: lockp->unlock(); if (result) { // Only new ACQUIRE should get here. // All RELEASE and CHECK and recursive ACQUIRE are // handled by the per-thread caches above. if (why == RELEASE) { // Probably some thread is incorrectly exiting // while the object is held by another thread. return nil; } if (why != ACQUIRE) _objc_fatal("id2data is buggy"); if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS if (!fastCacheOccupied) { // Save in fast thread cache tls_set_direct(SYNC_DATA_DIRECT_KEY, result); tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1); } else #endif { // Save in thread cache if (!cache) cache = fetch_cache(YES); cache->list[cache->used].data = result; cache->list[cache->used].lockCount = 1; cache->used++; } }
return result; }
static SyncCache *fetch_cache(bool create) { _objc_pthread_data *data; data = _objc_fetch_pthread_data(create); if (!data) returnNULL;
if (!data->syncCache) { if (!create) { returnNULL; } else { int count = 4; data->syncCache = (SyncCache *) calloc(1, sizeof(SyncCache) + count*sizeof(SyncCacheItem)); data->syncCache->allocated = count; } }
// Make sure there's at least one open slot in the list. if (data->syncCache->allocated == data->syncCache->used) { data->syncCache->allocated *= 2; data->syncCache = (SyncCache *) realloc(data->syncCache, sizeof(SyncCache) + data->syncCache->allocated * sizeof(SyncCacheItem)); }
return data->syncCache; }
/*********************************************************************** * _objc_fetch_pthread_data * Fetch objc's pthread data for this thread. * If the data doesn't exist yet and create is NO, return NULL. * If the data doesn't exist yet and create is YES, allocate and return it. **********************************************************************/ _objc_pthread_data *_objc_fetch_pthread_data(bool create) { _objc_pthread_data *data;
data = (_objc_pthread_data *)tls_get(_objc_pthread_key); if (!data && create) { data = (_objc_pthread_data *) calloc(1, sizeof(_objc_pthread_data)); tls_set(_objc_pthread_key, data); }
/* Fast cache: two fixed pthread keys store a single SyncCacheItem. This avoids malloc of the SyncCache for threads that only synchronize a single object at a time. SYNC_DATA_DIRECT_KEY == SyncCacheItem.data SYNC_COUNT_DIRECT_KEY == SyncCacheItem.lockCount */
#if SUPPORT_DIRECT_THREAD_KEYS // Check per-thread single-entry fast cache for matching object bool fastCacheOccupied = NO; SyncData *data = (SyncData *)tls_get_direct(SYNC_DATA_DIRECT_KEY); if (data) { fastCacheOccupied = YES;
if (data->object == object) { // Found a match in fast cache. uintptr_t lockCount;
result = data; lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY); if (result->threadCount <= 0 || lockCount <= 0) { //从缓存中拿出来的SyncData,它的threadCount,lockCount不可能为0,因为新建锁时会设置为1,然后才丢到缓存中去的。下面的SyncCache同样的道理。 _objc_fatal("id2data fastcache is buggy"); }
switch(why) { case ACQUIRE: { lockCount++; tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); break; } case RELEASE: lockCount--; tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)lockCount); if (lockCount == 0) { // remove from fast cache tls_set_direct(SYNC_DATA_DIRECT_KEY, NULL); // atomic because may collide with concurrent ACQUIRE OSAtomicDecrement32Barrier(&result->threadCount); } break; case CHECK: // do nothing break; }
// Check per-thread cache of already-owned locks for matching object SyncCache *cache = fetch_cache(NO); if (cache) { unsignedint i; for (i = 0; i < cache->used; i++) { SyncCacheItem *item = &cache->list[i]; if (item->data->object != object) continue;
// Found a match. result = item->data; if (result->threadCount <= 0 || item->lockCount <= 0) { _objc_fatal("id2data cache is buggy"); }
switch(why) { case ACQUIRE: item->lockCount++; break; case RELEASE: item->lockCount--; if (item->lockCount == 0) { // remove from per-thread cache cache->list[i] = cache->list[--cache->used]; // atomic because may collide with concurrent ACQUIRE OSAtomicDecrement32Barrier(&result->threadCount); } break; case CHECK: // do nothing break; }
// remove from per-thread cache cache->list[i] = cache->list[--cache->used]; // atomic because may collide with concurrent ACQUIRE OSAtomicDecrement32Barrier(&result->threadCount);
// Thread cache didn't find anything. // Walk in-use list looking for matching object // Spinlock prevents multiple threads from creating multiple // locks for the same new object. // We could keep the nodes in some hash table if we find that there are // more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{ SyncData* p; SyncData* firstUnused = NULL; for (p = *listp; p != NULL; p = p->nextData) { if ( p->object == object ) { result = p; // atomic because may collide with concurrent RELEASE OSAtomicIncrement32Barrier(&result->threadCount); goto done; } if ( (firstUnused == NULL) && (p->threadCount == 0) ) firstUnused = p; }
// no SyncData currently associated with object if ( (why == RELEASE) || (why == CHECK) ) goto done;
// an unused one was found, use it if ( firstUnused != NULL ) { result = firstUnused; result->object = (objc_object *)object; result->threadCount = 1; goto done; } } ......
// an unused one was found, use it if ( firstUnused != NULL ) { result = firstUnused; result->object = (objc_object *)object; result->threadCount = 1; goto done; }
// Thread cache didn't find anything. // Walk in-use list looking for matching object // Spinlock prevents multiple threads from creating multiple // locks for the same new object. // We could keep the nodes in some hash table if we find that there are // more than 20 or so distinct locks active, but we don't do that now.
lockp->lock();
{ SyncData* p; SyncData* firstUnused = NULL; for (p = *listp; p != NULL; p = p->nextData) { if ( p->object == object ) { result = p; // atomic because may collide with concurrent RELEASE OSAtomicIncrement32Barrier(&result->threadCount); goto done; } if ( (firstUnused == NULL) && (p->threadCount == 0) ) firstUnused = p; }
// no SyncData currently associated with object if ( (why == RELEASE) || (why == CHECK) ) goto done;
// an unused one was found, use it if ( firstUnused != NULL ) { result = firstUnused; result->object = (objc_object *)object; result->threadCount = 1; goto done; } }
// Allocate a new SyncData and add to list. // XXX allocating memory with a global lock held is bad practice, // might be worth releasing the lock, allocating, and searching again. // But since we never free these guys we won't be stuck in allocation very often. posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); result->object = (objc_object *)object; result->threadCount = 1; new (&result->mutex) recursive_mutex_t(fork_unsafe_lock); result->nextData = *listp; *listp = result;
done: lockp->unlock(); if (result) { // Only new ACQUIRE should get here. // All RELEASE and CHECK and recursive ACQUIRE are // handled by the per-thread caches above. if (why == RELEASE) { // Probably some thread is incorrectly exiting // while the object is held by another thread. return nil; } if (why != ACQUIRE) _objc_fatal("id2data is buggy"); if (result->object != object) _objc_fatal("id2data is buggy");
#if SUPPORT_DIRECT_THREAD_KEYS if (!fastCacheOccupied) { // Save in fast thread cache tls_set_direct(SYNC_DATA_DIRECT_KEY, result); tls_set_direct(SYNC_COUNT_DIRECT_KEY, (void*)1); } else #endif { // Save in thread cache if (!cache) cache = fetch_cache(YES); cache->list[cache->used].data = result; cache->list[cache->used].lockCount = 1; cache->used++; } }
return result;
同样创建新的SyncData时也是在自旋锁保护区里的,主要的创建代码为:
1 2 3 4 5 6 7 8 9 10
// Allocate a new SyncData and add to list. // XXX allocating memory with a global lock held is bad practice, // might be worth releasing the lock, allocating, and searching again. // But since we never free these guys we won't be stuck in allocation very often. posix_memalign((void **)&result, alignof(SyncData), sizeof(SyncData)); result->object = (objc_object *)object; //记录传入的对象地址 result->threadCount = 1; new (&result->mutex) recursive_mutex_t(fork_unsafe_lock); //创建一把新锁 result->nextData = *listp; //添加到链表里,注意这里是添加到链表头部 *listp = result;
// End synchronizing on 'obj'. // Returns OBJC_SYNC_SUCCESS or OBJC_SYNC_NOT_OWNING_THREAD_ERROR intobjc_sync_exit(id obj) { int result = OBJC_SYNC_SUCCESS; if (obj) { SyncData* data = id2data(obj, RELEASE); if (!data) { result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR; } else { bool okay = data->mutex.tryUnlock(); if (!okay) { result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR; } } } else { // @synchronized(nil) does nothing }
typedefstructalignas(CacheLineSize) SyncData { structSyncData* nextData; DisguisedPtr<objc_object> object; int32_t threadCount; // number of THREADS using this block recursive_mutex_t mutex; } SyncData;