为什么要进行内存对齐
主要有两个原因:1.内存对齐后可以减少内存的读取次数,提高内存的访问效率。2.提高程序的可移植性,因为有的平台对寻址的起始地址有要求。
现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的计算机系统对数据在内存中存放的位置是有限制的,它们会要求这些数据的内存首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
注:某个数是4的倍数,不一定就是8的倍数,比如4、12、20、28、36。但反过来是8的倍数则必定是4的倍数。
内存对齐主要是为了提高内存的访问效率,CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU,字长为4字节,那么CPU访问内存的单位也是4字节,即一次读取4个字节的内存。又比如intel 32位cpu,每个总线周期都是从偶数地址开始读取32位的内存数据,如果数据存放地址不是从偶数开始,则可能出现需要两个总线周期才能读取到想要的数据,因此需要在内存中存放数据时进行对齐。
总之一句话,只有当数据的首地址为某个数k(通常它为4或8)的倍数时(偶数地址),CPU需要进行数据剔除的情况才会越少发生。当剔除操作无法避免时,剔除次数越少越好,如果数据的首地址是奇数,那么CPU需要剔除前后的数据。而如果是偶数则最好情况下只需要剔除前面或后面的数据。char类型的变量因为只占1个字节就随便了。
假如没有内存对齐机制,数据可以在任意内存地址处开始存放:
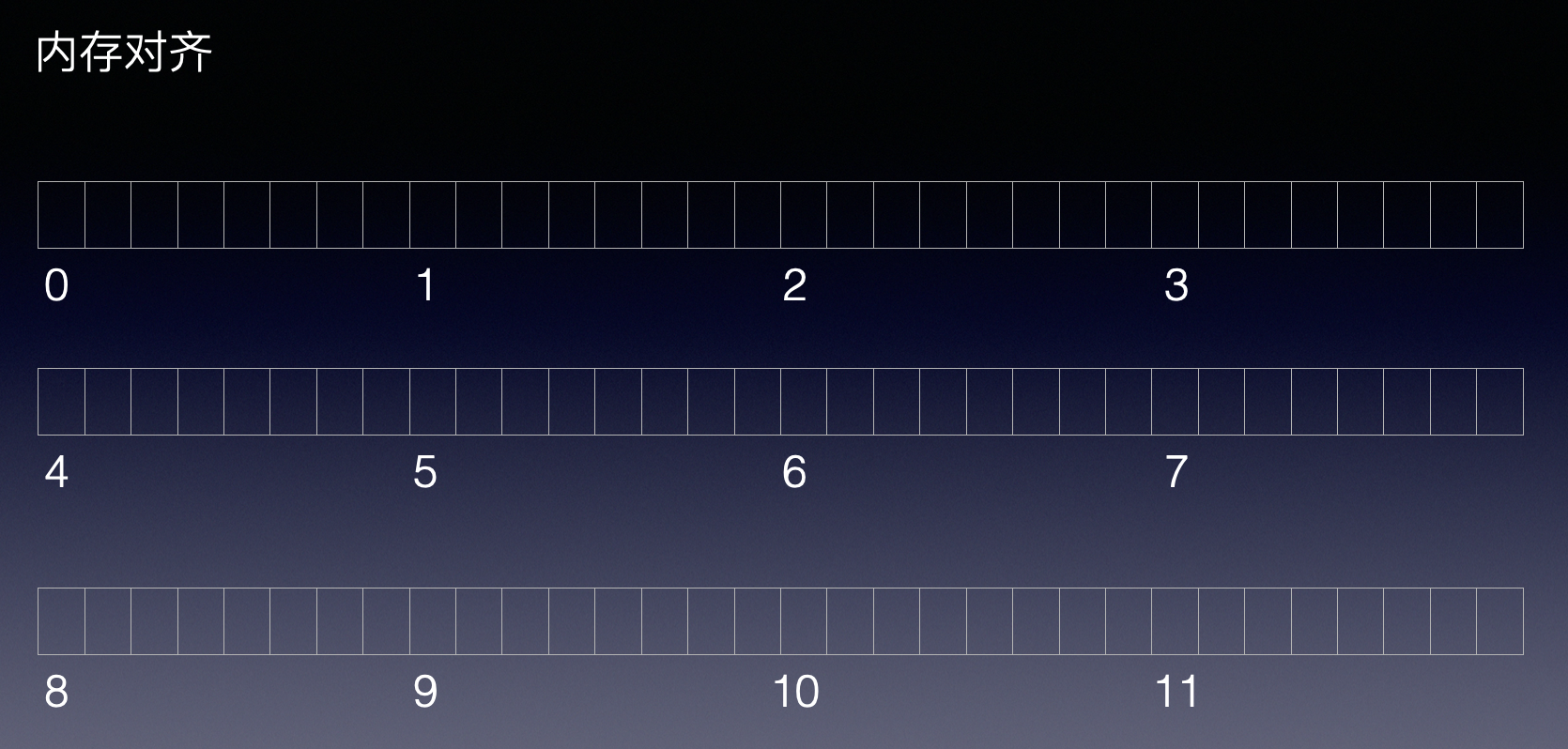
现在一个int变量存放在从地址1开始的连续四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器.这需要做很多工作.
如果int变量存放在从地址4开始的连续四个字节地址中,就可以一次读取完数据。
所以int变量的内存首地址通常在4的倍数的地址处开始,比如上面的编号为4或8的地址处,而不可能是2或5这样的地址处。
1 | printf("sizeof(char):%lu, sizeof(int):%lu\n", sizeof(char), sizeof(int)); |
打印:
1 | sizeof(char):1, sizeof(int):4 |
会发现:
- 栈是往下增长的,由高地址到低地址。
- char占1个字节所以放哪里都是一样的,int占4个字节为了提高CPU存取效率所以进行了内存对齐,首地址选择了4的倍数的地址。
sizeof
sizeof 是一个关键字,用于判断变量或数据类型的字节大小。它并不是一个函数而是一个编译时运算符。字节数的计算在程序编译时进行,而不是在程序执行的过程中才计算出来。
sizeof 运算符可用于获取类、结构、共用体和其他用户自定义数据类型的大小。
内存对齐规则
对齐系数:
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。Xcode默认的对齐系数是8(不确定是否跟CPU的位数有关,32位的就是4,64位的就是8)。
对齐单位:
给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。即min(pack, 结构体中最长数据类型的长度)。如果是嵌套结构体那么计算对齐单位时需要不要考虑这个嵌套的结构体里的成员?实验了一下,貌似不需要考虑嵌套的结构体。
内存对齐规则:
(1) 元素对齐。结构体第一个成员的偏移量(offset)为0。下一个数据成员为基本数据类型的,则offset=整数倍的min(d, sizeof(member))。数据成员为结构体的,则offset=整数倍的min(pack, ss中最长数据类型的长度)。
(2) 总体对齐。结构体的总大小为对齐单位的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
上面的文字用公式表达就是:
1 | 1.已知对齐系数为p。 |
可以使用offsetof(type, member)查看结构体某个成员存储的位置偏移结构体首地址多少个字节。
基本数据类型需要对齐,结构体可以看成是一些基本数据类型的集合,因此结构体不仅需要整体对齐,其内部各变量的首地址也需要对齐。
Q:对齐规则为什么是这样的?不知道。为什么要定义一个对齐单位?
示例:
1 | - (void)test_memory_align { |
参考
拓展阅读
Generating Aligned Memory 有空看一下。
